The basic RAG pipeline involves embedding a user query, retrieving relevant documents to the query, and passing the documents to an LLM for generation of an answer grounded in the retrieved context as we seen through out this tutorial series.
%load_ext dotenv
%dotenv secrets/secrets.envWhen retrieving documents we usually rerank them based on a certain algorithm like Reciprocal Rank Fusion (RRF). Instead of providing all the documents retrieved as the context, reranking allows us to provide only top-k relevant documents saving the limited context length of most affordable LLMs.
In this section we implement two reranking-based retrieval methods, namely,
Reciprocal Rank Fusion (RRF)
Cohere Reranking
from langchain_community.document_loaders import PyPDFLoader, DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_classic import hub
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from typing import List
from langchain_classic.load import loads, dumpsloader = DirectoryLoader('data/',glob="*.pdf",loader_cls=PyPDFLoader)
documents = loader.load()
# Split text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=20)
text_chunks = text_splitter.split_documents(documents)
vectorstore = Chroma.from_documents(documents=text_chunks,
embedding=OpenAIEmbeddings(),
persist_directory="data/vectorstore")
vectorstore.persist()
retriever = vectorstore.as_retriever(search_kwargs={'k':5})/Users/sakunaharinda/Documents/Repositories/ragatouille-book/.venv/lib/python3.12/site-packages/pypdf/_crypt_providers/_cryptography.py:32: CryptographyDeprecationWarning: ARC4 has been moved to cryptography.hazmat.decrepit.ciphers.algorithms.ARC4 and will be removed from cryptography.hazmat.primitives.ciphers.algorithms in 48.0.0.
from cryptography.hazmat.primitives.ciphers.algorithms import AES, ARC4
/var/folders/lk/t9rd7y8534757z3rjdvbmhm40000gn/T/ipykernel_81834/1635720911.py:12: LangChainDeprecationWarning: Since Chroma 0.4.x the manual persistence method is no longer supported as docs are automatically persisted.
vectorstore.persist()
Reciprocal Rank Fusion¶
def rrf(results: List[List], k=60):
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples, each containing the document and its fused score
return reranked_resultsfrom langchain_core.prompts import ChatPromptTemplate
question = "What is QLoRA?"
prompt = ChatPromptTemplate.from_template(
"""
You are an intelligent assistant. Your task is to generate 4 questions based on the provided question in different wording and different perspectives to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question}
"""
)
generate_queries = (
{"question": RunnablePassthrough()}
| prompt
| ChatOpenAI(model='gpt-4', temperature=0.7)
| StrOutputParser()
| (lambda x: x.split("\n"))
)
fusion_retrieval_chain = (
{'question': RunnablePassthrough()}
| generate_queries
| retriever.map()
| rrf
)
fusion_retrieval_chain.invoke(question)/var/folders/lk/t9rd7y8534757z3rjdvbmhm40000gn/T/ipykernel_81834/2894234141.py:21: LangChainBetaWarning: The function `loads` is in beta. It is actively being worked on, so the API may change.
(loads(doc), score)
[(Document(metadata={'page': 0, 'source': 'data/QLoRA.pdf'}, page_content='Quantization to reduce the average memory footprint by quantizing the quantization\nconstants, and (c) Paged Optimizers to manage memory spikes. We use QLORA\nto finetune more than 1,000 models, providing a detailed analysis of instruction\nfollowing and chatbot performance across 8 instruction datasets, multiple model\ntypes (LLaMA, T5), and model scales that would be infeasible to run with regular\nfinetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA'),
0.09654296563504655),
(Document(metadata={'source': 'data/QLoRA.pdf', 'page': 21}, page_content='A QLoRA vs Standard Finetuning Experimental Setup Details\nA.1 Hyperparameters for QL ORA\nWe do a hyperparameter search for LoRA over the following variables: LoRA dropout { 0.0, 0.05,\n0.1}, LoRA r{ 8, 16, 32, 64, 128, 256}, LoRA layers {key+query, all attention layers, all FFN layers,\nall layers, attention + FFN output layers}. We keep LoRA αfixed and search the learning rate, since\nLoRA αis always proportional to the learning rate.'),
0.08119118967876239),
(Document(metadata={'page': 21, 'source': 'data/QLoRA.pdf'}, page_content='A QLoRA vs Standard Finetuning Experimental Setup Details\nA.1 Hyperparameters for QL ORA\nWe do a hyperparameter search for LoRA over the following variables: LoRA dropout { 0.0, 0.05,\n0.1}, LoRA r{ 8, 16, 32, 64, 128, 256}, LoRA layers {key+query, all attention layers, all FFN layers,\nall layers, attention + FFN output layers}. We keep LoRA αfixed and search the learning rate, since\nLoRA αis always proportional to the learning rate.'),
0.08018312516263336),
(Document(metadata={'source': 'data/QLoRA.pdf', 'page': 0}, page_content='Quantization to reduce the average memory footprint by quantizing the quantization\nconstants, and (c) Paged Optimizers to manage memory spikes. We use QLORA\nto finetune more than 1,000 models, providing a detailed analysis of instruction\nfollowing and chatbot performance across 8 instruction datasets, multiple model\ntypes (LLaMA, T5), and model scales that would be infeasible to run with regular\nfinetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA'),
0.0648313492063492)]def format_context(documents: List):
return "\n\n".join([doc[0].page_content for doc in documents])
prompt = ChatPromptTemplate.from_template(
"""
Asnwer the given question using the provided context.\n\nContext: {context}\n\nQuestion: {question}
"""
)
rag_with_rrf_chain = (
{'context': fusion_retrieval_chain | format_context, 'question': RunnablePassthrough()}
| prompt
| ChatOpenAI(model='gpt-4', temperature=0)
| StrOutputParser()
)
rag_with_rrf_chain.invoke(question)'The context does not provide a specific definition or explanation of what QLoRA is.'Cohere Reranking¶
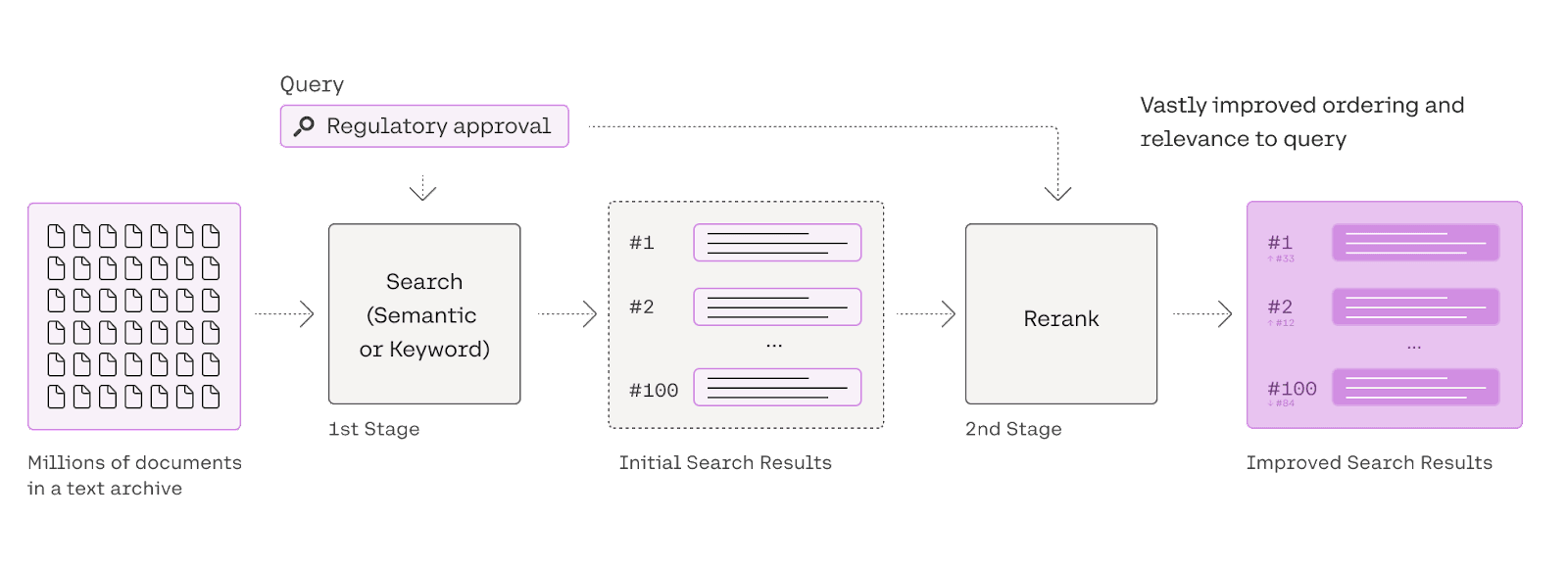 |
|---|
| Cohere Reranking process |
Cohere uses a tranformer model to rerank relevant documents per a user’s query. This means that companies can retain an existing keyword-based (also called “lexical”) or semantic search system for the first-stage retrieval and integrate the Rerank endpoint in the second stage re-ranking. Since this technique reranks the documents based on their content instead of their frquecy in the retrieved document set (as seen in RRF), this is much more accurate.
To begin with, we define the Cohere Reranker with the model rerank-english-v2.0 to retrieve top 3 documents for the given question. Then we pass the reranking model together with our base retriever that provides the initial document set to rank.
from langchain_community.llms import Cohere
from langchain_classic.retrievers import ContextualCompressionRetriever
from langchain_classic.retrievers.document_compressors import CohereRerank
compressor = CohereRerank(model="rerank-v4.0-fast", top_n=3)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(question)
compressed_docs[Document(metadata={'page': 0, 'source': 'data/QLoRA.pdf', 'relevance_score': 0.7777053}, page_content='Quantization to reduce the average memory footprint by quantizing the quantization\nconstants, and (c) Paged Optimizers to manage memory spikes. We use QLORA\nto finetune more than 1,000 models, providing a detailed analysis of instruction\nfollowing and chatbot performance across 8 instruction datasets, multiple model\ntypes (LLaMA, T5), and model scales that would be infeasible to run with regular\nfinetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA'),
Document(metadata={'source': 'data/QLoRA.pdf', 'page': 0, 'relevance_score': 0.7777053}, page_content='Quantization to reduce the average memory footprint by quantizing the quantization\nconstants, and (c) Paged Optimizers to manage memory spikes. We use QLORA\nto finetune more than 1,000 models, providing a detailed analysis of instruction\nfollowing and chatbot performance across 8 instruction datasets, multiple model\ntypes (LLaMA, T5), and model scales that would be infeasible to run with regular\nfinetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA'),
Document(metadata={'source': 'data/QLoRA.pdf', 'page': 0, 'relevance_score': 0.7777053}, page_content='Quantization to reduce the average memory footprint by quantizing the quantization\nconstants, and (c) Paged Optimizers to manage memory spikes. We use QLORA\nto finetune more than 1,000 models, providing a detailed analysis of instruction\nfollowing and chatbot performance across 8 instruction datasets, multiple model\ntypes (LLaMA, T5), and model scales that would be infeasible to run with regular\nfinetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA')]prompt = ChatPromptTemplate.from_template(
"""
Asnwer the given question using the provided context.\n\nContext: {context}\n\nQuestion: {question}
"""
)
cohere_with_rag_chain = (
{'context': compression_retriever, 'question': RunnablePassthrough()}
| prompt
| ChatOpenAI(model='gpt-4', temperature=0)
| StrOutputParser()
)
cohere_with_rag_chain.invoke(question)
'The context does not provide a specific definition or description of what QLoRA is.'The LangSmith trace for the Cohere reranking will look like this.